As renovações do Trial do Microsoft Fabric acabaram, e agora?

Durante meses, muitas empresas trataram o Microsoft Fabric Trial como uma ponte confortável: o ambiente funcionava, os workspaces seguiam ativos, os relatórios eram atualizados e a discussão sobre capacidade ficava para depois. Esse “depois” chegou.
Nas últimas semanas, organizações que vinham contando com renovações sucessivas do Trial começaram a perceber que a renovação já não estava mais disponível para muitos tenants. O impacto aparece rápido: pipelines param, modelos semânticos deixam de atualizar, relatórios críticos ficam indisponíveis e a área de TI é chamada para explicar por que uma plataforma que estava “rodando sem custo” agora exige uma decisão de arquitetura, governança e orçamento.
Este artigo foi escrito para gestores de TI, gestores de contas, líderes de dados e times técnicos que precisam transformar esse susto em uma decisão bem conduzida. A pergunta principal não é apenas “qual capacidade devo contratar?”. A pergunta correta é: qual arquitetura, governança e modelo operacional precisamos para que o Fabric entregue valor com custo previsível.
Resumo executivo
O fim das renovações do Trial do Microsoft Fabric expôs uma realidade que estava escondida em muitos ambientes: várias empresas passaram a operar workloads reais em uma capacidade temporária, generosa e sem o mesmo rigor de custo que seria exigido em produção.
Para a liderança, isso significa que a decisão não deve ser apenas comprar uma capacidade rapidamente. É preciso entender consumo, criticidade, performance, arquitetura, governança e modelo de contratação.
Para os times técnicos, o alerta é direto: ambientes com modelos semânticos mal desenhados, Dataflows pesados, pipelines sem incrementalidade e notebooks sem padrão tendem a consumir mais capacidade do que deveriam. Quando o Trial acaba, esses problemas deixam de ser invisíveis.
O que é o Microsoft Fabric e por que capacidade importa
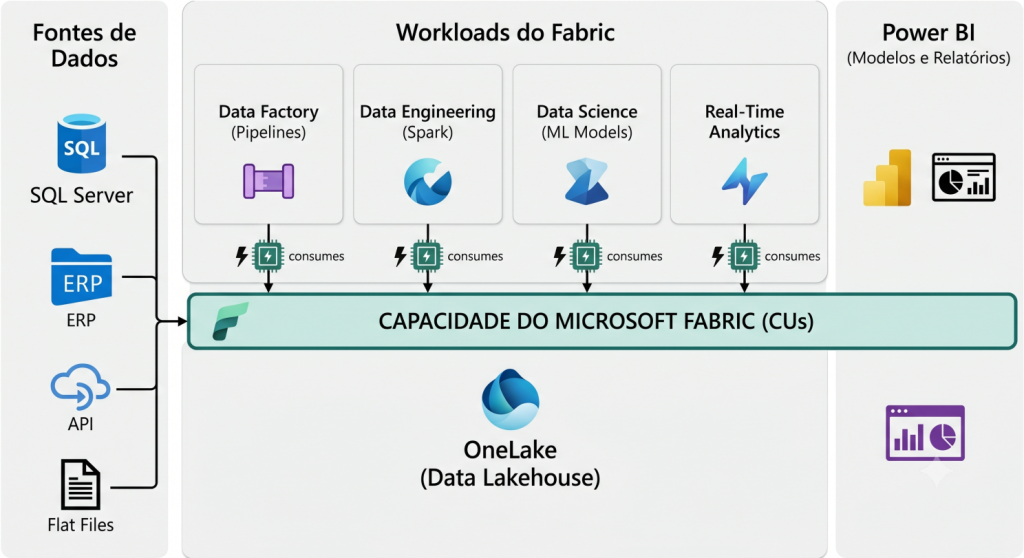
O Microsoft Fabric é uma plataforma SaaS de dados e analytics que reúne, em uma experiência integrada, recursos que antes costumavam ser tratados como peças separadas: ingestão de dados, engenharia de dados, lakehouse, warehouse, ciência de dados, inteligência em tempo real e Power BI.
Na prática, ele aproxima diferentes perfis de profissionais em uma mesma plataforma:
Esse desenho é poderoso porque reduz atritos entre áreas. Mas ele também muda a natureza da conversa sobre custo. No Fabric, o consumo relevante não é apenas “quantas pessoas acessam relatórios”. O ponto central passa a ser quanto processamento a organização consome ao mover, transformar, armazenar, consultar e entregar dados.
Como funciona a capacidade no Microsoft Fabric
Uma capacidade do Fabric é um bloco de processamento compartilhado pelos workloads associados a ela. Pense nela como o motor que sustenta os workspaces: quando um pipeline roda, um notebook processa dados, um warehouse recebe consultas ou um modelo semântico é atualizado, esse motor é consumido.
Entre os itens que podem consumir capacidade estão:
-
Pipelines de dados.
-
Dataflows Gen2.
-
Notebooks Spark.
-
Lakehouses.
-
Warehouses.
-
KQL databases e cargas de Real-Time Intelligence.
-
Atualizações de modelos semânticos.
-
Consultas em relatórios Power BI.
-
Operações de Direct Lake.
-
Processos de ingestão, transformação e leitura de dados.
A unidade usada para dimensionar esse consumo é baseada em Capacity Units, conhecidas como CUs. Cada SKU do Fabric entrega uma quantidade diferente de CUs. Quanto maior o SKU, maior a quantidade de processamento disponível.
Exemplos comuns de tiers:

A armadilha está em assumir que a capacidade necessária deve ser definida apenas pelo número de usuários. Em Fabric, um ambiente com poucos usuários pode consumir muito se tiver refreshes pesados, notebooks mal parametrizados, pipelines reprocessando histórico inteiro todos os dias ou modelos semânticos com cardinalidade explosiva. Da mesma forma, uma empresa com muitos usuários pode operar com previsibilidade quando a arquitetura é bem desenhada.
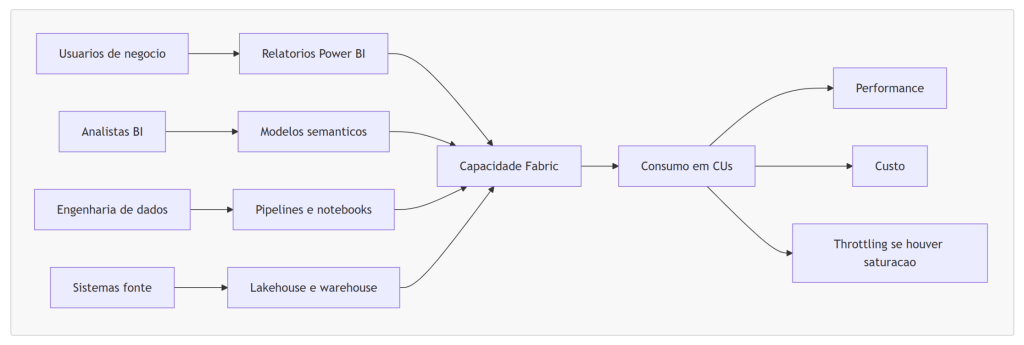
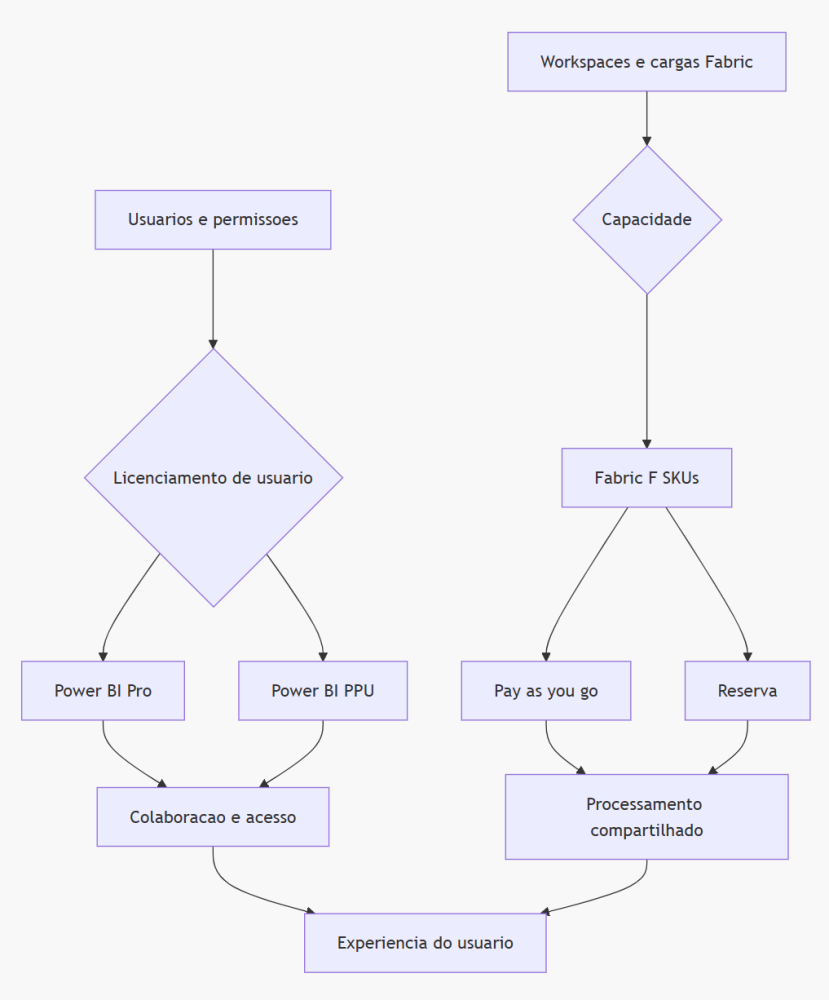
Pay-as-you-go, instância reservada, Pro e PPU: coisas diferentes que muita gente mistura
Uma confusão comum em conversas executivas é misturar licença de usuário com capacidade computacional. São componentes relacionados, mas não são a mesma coisa.
As licenças Power BI Pro e Power BI Premium Per User (PPU) são licenças por usuário. Elas controlam recursos e permissões de colaboração, publicação, compartilhamento e consumo em determinados cenários de Power BI. Já a capacidade Fabric é o recurso computacional que sustenta workloads do Fabric e workspaces atribuídos a essa capacidade.
Em termos simples: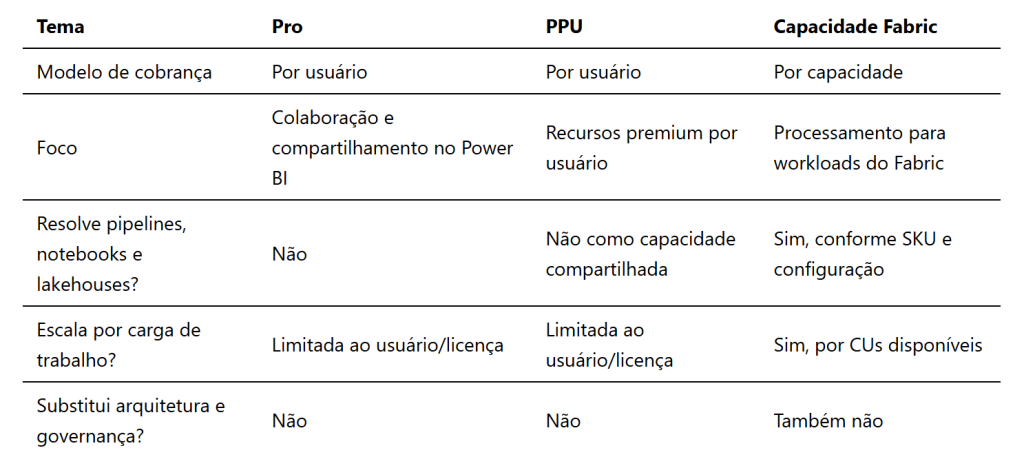
Também existem formas diferentes de contratar capacidade Fabric:

Um detalhe importante para gestores: em cenários de Power BI, capacidades F64 ou superiores costumam estar associadas a benefícios mais próximos do antigo Premium por capacidade, incluindo cenários de consumo por usuários Free conforme as regras vigentes de licenciamento. Abaixo desse patamar, licenças Pro ou PPU continuam sendo parte relevante da conta para colaboração e consumo de conteúdo Power BI.
Para gestores, a leitura principal é: licença de usuário não compensa arquitetura ineficiente, e capacidade maior não corrige governança fraca. Uma empresa pode contratar um SKU alto e continuar tendo lentidão, custo excessivo e baixa confiabilidade se o ambiente estiver tecnicamente desorganizado.
O Trial do Microsoft Fabric: por que ele mascarou o problema
O Trial do Microsoft Fabric foi desenhado para permitir que empresas experimentassem recursos da plataforma antes de contratar uma capacidade. Ele libera um período de avaliação, historicamente apresentado como uma janela de aproximadamente 60 dias, para que usuários e organizações testem workloads como lakehouse, warehouse, pipelines, notebooks e integrações com Power BI.
Na prática, o Trial cumpriu um papel importante: acelerou a adoção. Times conseguiram testar o Fabric sem passar por um ciclo completo de contratação, aprovação orçamentária e provisionamento. O problema é que, em muitas empresas, o Trial deixou de ser ambiente de validação e virou base operacional.
Isso aconteceu por três razões:
-
O acesso inicial era simples.
-
A capacidade disponível durante o Trial era generosa em relação ao orçamento real de muitas empresas.
-
A possibilidade de renovação, ainda que por liberalidade e não como estratégia permanente, criou a sensação de continuidade.
O efeito colateral foi previsível: algumas empresas amadureceram tecnicamente; outras apenas acumularam artefatos. Foram surgindo workspaces, pipelines, modelos, relatórios, dataflows e notebooks sem uma avaliação séria de custo, criticidade, dono, padrão de desenvolvimento ou plano de sustentação.
Enquanto o Trial renovava, a conta parecia não chegar. Agora ela chegou.
O problema: quando o Trial acaba, a arquitetura aparece
Imagine uma segunda-feira pela manhã. O diretor comercial abre o dashboard de vendas e percebe que os números não atualizaram. O gerente de contas, que tinha reunião com um cliente estratégico, encontra indicadores defasados. A área financeira pede uma posição de margem por região, mas o modelo semântico falhou no refresh. O time técnico olha o histórico e percebe que pipelines, dataflows e notebooks dependiam de um workspace que estava em Trial.
O problema não começou na segunda-feira. Ele apenas ficou visível naquele dia.
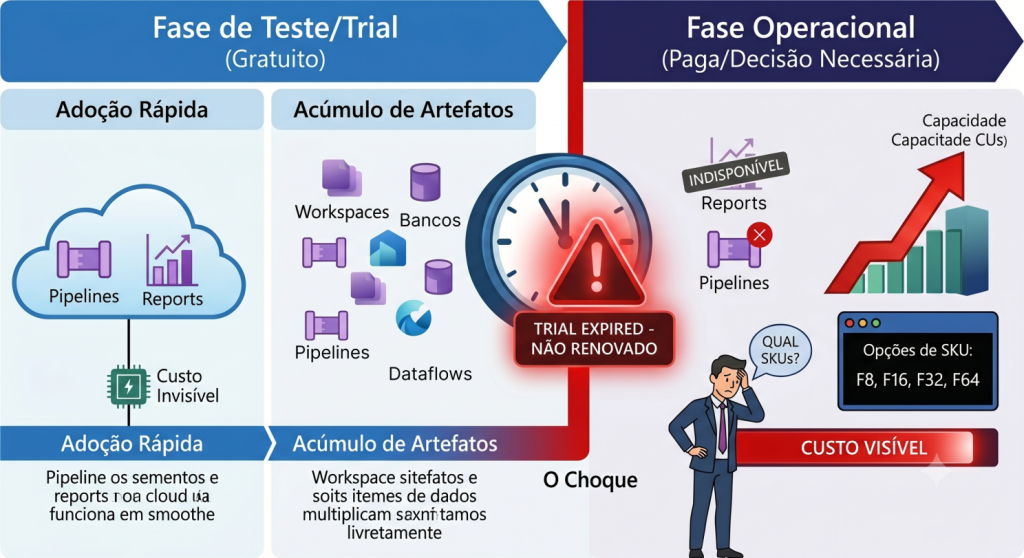
Quando o Trial termina e não há uma capacidade adequada atribuída aos workspaces, a empresa pode enfrentar impactos como:
-
Interrupção de workloads do Fabric.
-
Falhas em atualizações de modelos semânticos.
-
Indisponibilidade de itens associados a workspaces sem capacidade.
-
Atrasos em pipelines e processos de ingestão.
-
Perda de confiança nos indicadores.
-
Pressão emergencial para contratar uma capacidade sem diagnóstico.
-
Decisões de negócio tomadas com dados desatualizados.
O ponto mais sensível é que muitas organizações estavam usando uma capacidade de Trial equivalente a um patamar alto para sua realidade orçamentária. Em diversos cenários, o Trial oferecia uma experiência próxima de uma capacidade F64. Só que uma F64 pode estar muito acima do budget aprovado para empresas que ainda estão em fase inicial de maturidade no Fabric.
Isso cria um choque: o ambiente foi construído e testado em uma condição generosa, mas a contratação real talvez precise começar em F8, F16 ou F32. Se nada for otimizado, a organização tende a concluir que “Fabric é caro”. Na maioria das vezes, a leitura correta é outra: o ambiente foi criado sem disciplina de consumo.
Os principais agressores de capacidade
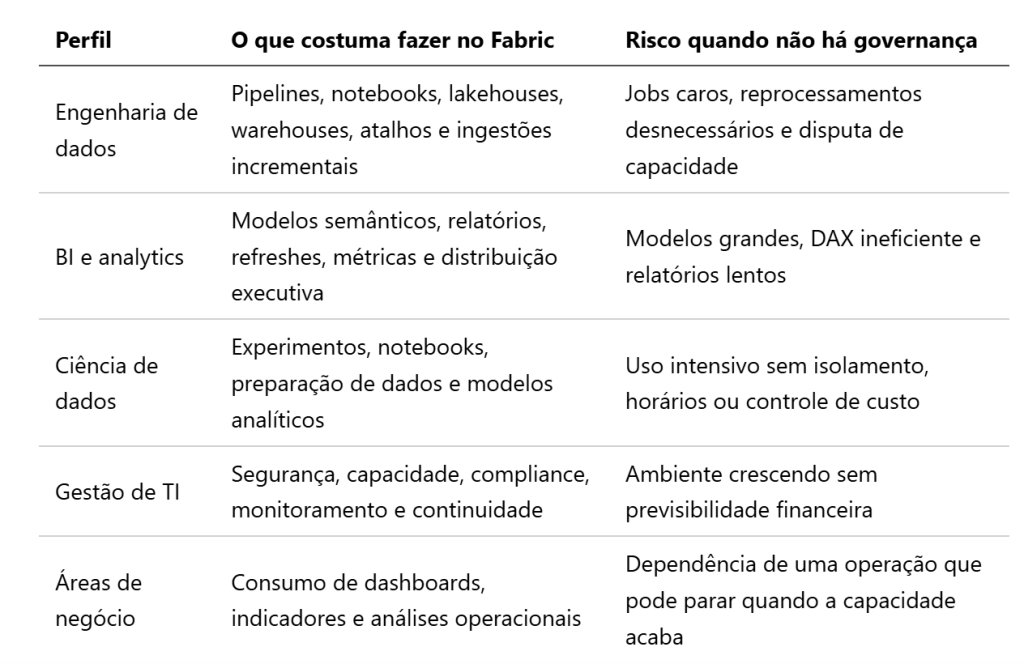
Antes de contratar uma capacidade maior, é preciso descobrir quem está consumindo, quando consome e por quê. Em projetos reais, os maiores consumidores raramente são uma surpresa para o time técnico. O que falta é visibilidade consolidada para transformar percepção em decisão.
Entre os agressores mais comuns estão:
1. Modelos semânticos mal modelados
Modelos semânticos são um dos pontos mais importantes da experiência de analytics. Um bom modelo entrega relatórios rápidos, DAX simples e manutenção previsível. Um modelo ruim faz o oposto: consome mais memória, exige mais processamento, demora para atualizar e torna cada nova métrica um risco.
Problemas frequentes:
-
Tabelas fato e dimensão sem desenho claro.
-
Relacionamentos ambíguos ou bidirecionais sem necessidade.
-
Colunas de alta cardinalidade carregadas sem uso analítico.
-
Medidas DAX complexas compensando falhas de modelagem.
-
Cálculos linha a linha em grandes volumes.
-
Falta de agregações, particionamento ou incremental refresh.
Para a gestão, isso significa que o custo não está apenas no volume de dados. Está também na forma como os dados são modelados.
2. Dataflows usados como motor de engenharia pesada
Dataflows podem ser úteis, mas muitas empresas passaram a usá-los como solução universal para ingestão e transformação. O resultado pode ser uma cadeia difícil de monitorar, pouco modular e custosa quando há grandes volumes ou transformações complexas.
Sinais de alerta:
-
Dataflows reprocessando bases completas diariamente.
-
Transformações pesadas em Power Query sem estratégia incremental.
-
Dependências entre dataflows sem desenho operacional claro.
-
Falhas intermitentes difíceis de rastrear.
-
Lógica crítica espalhada em múltiplos objetos.
Em muitos casos, pipelines e notebooks oferecem mais controle, rastreabilidade e eficiência para cargas corporativas.
3. Pipelines sem desenho incremental
Um pipeline que reprocessa tudo todos os dias pode funcionar no Trial. Em produção, ele vira custo recorrente. A arquitetura precisa separar carga histórica, carga incremental, tratamento de exceções e reprocessamento sob demanda.
Boas perguntas técnicas:
-
O pipeline sabe identificar apenas dados novos ou alterados?
-
Existe watermark de carga?
-
Há particionamento por data, domínio ou fonte?
-
O reprocessamento é controlado ou sempre total?
-
O horário de execução compete com refreshes executivos?
4. Notebooks sem padronização
Notebooks são poderosos, especialmente para engenharia de dados e ciência de dados. Mas, sem padrão, podem virar caixas-pretas caras.
Riscos comuns:
-
Execuções manuais sem registro operacional.
-
Código experimental promovido para produção sem revisão.
-
Leitura e gravação repetida de grandes volumes.
-
Falta de parametrização.
-
Ausência de versionamento e CI/CD.
5. Arquitetura que duplica dados sem necessidade
O Fabric oferece recursos modernos como OneLake, shortcuts, mirroring e Direct Lake. Quando esses recursos são ignorados, a empresa pode acabar copiando dados várias vezes: do sistema de origem para uma área intermediária, depois para outro repositório, depois para um modelo importado, depois para uma camada de consumo.
Nem toda duplicação é errada. Às vezes ela é necessária por performance, governança ou isolamento. O problema é duplicar por falta de arquitetura.
O que fazer agora: a resposta não é comprar no escuro
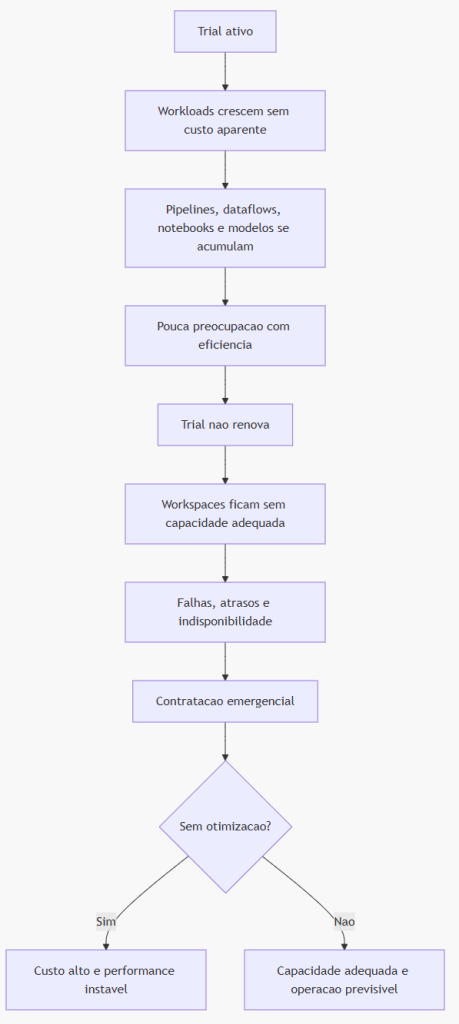
Quando o Trial acaba, a reação natural é procurar o SKU que “faça tudo voltar”. Essa urgência é compreensível, mas perigosa. Comprar capacidade sem diagnóstico pode resolver o incidente e criar um problema financeiro recorrente.
O caminho mais maduro combina três frentes:
-
Continuidade: garantir que cargas críticas voltem a operar.
-
Diagnóstico: identificar consumo, gargalos, agressores e dependências.
-
Otimização: reduzir desperdício para operar no menor tier viável com segurança

Para gestores, a recomendação é clara: não transforme uma decisão emergencial em contrato permanente sem medir o ambiente. Para times técnicos, o alerta é igualmente direto: o fim do Trial expõe a qualidade real da arquitetura.
Como analisar o ambiente Fabric
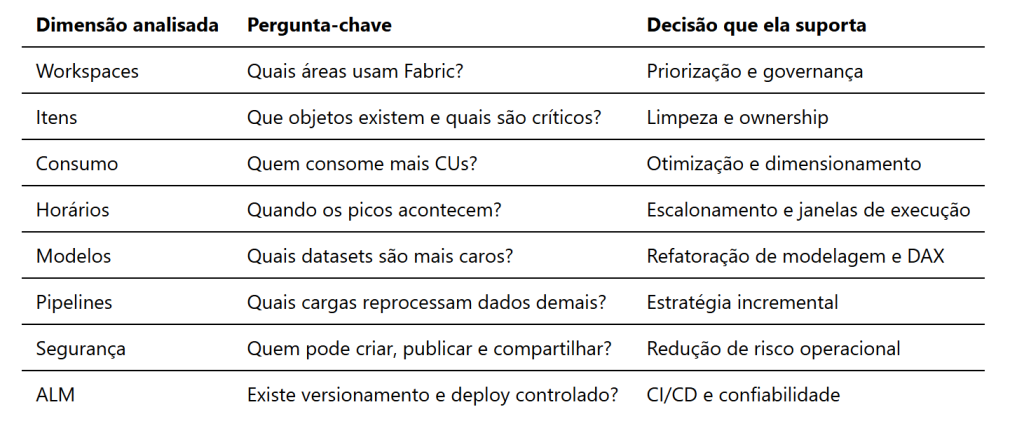
A análise deve começar com inventário e observabilidade. Antes de otimizar, é preciso saber o que existe.
Um diagnóstico bem conduzido deve responder:
-
Quais workspaces dependiam do Trial?
-
Quais itens existem em cada workspace?
-
Quais workloads são críticos para o negócio?
-
Quais processos rodam em horário comercial?
-
Quais refreshes falham ou demoram demais?
-
Quais modelos semânticos são mais pesados?
-
Quais pipelines ou notebooks consomem mais capacidade?
-
Existem cargas duplicadas entre áreas?
-
Quem é o dono de cada artefato?
-
Há separação entre desenvolvimento, homologação e produção?
Ferramentas como o app de métricas de capacidade do Fabric, logs de execução, histórico de refresh, lineage view, monitoramento de pipelines e revisões de modelos ajudam a formar essa visão.
Um inventário executivo pode organizar os achados assim:
Otimização: como reduzir consumo sem reduzir valor
O objetivo de uma otimização bem feita não é simplesmente “baratear”. É entregar o mesmo valor, ou mais, com menos desperdício e maior previsibilidade.
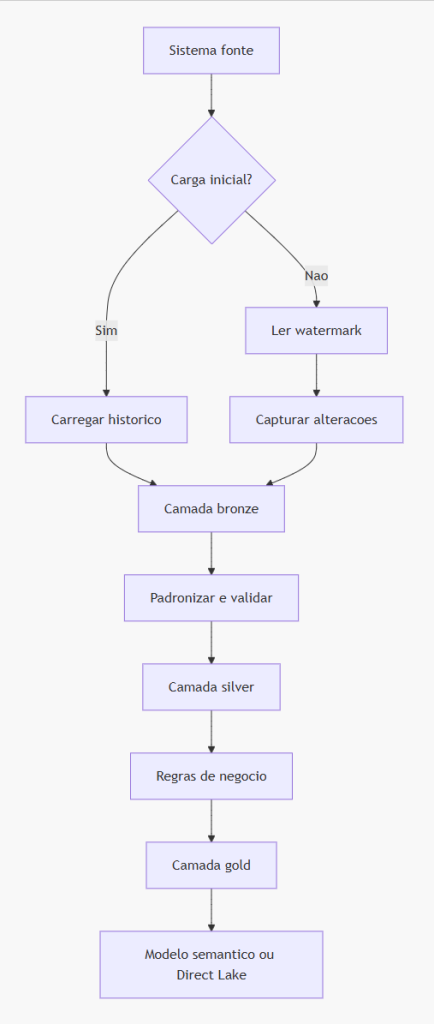
Arquitetura incremental de ingestão
Uma das formas mais eficientes de reduzir consumo é parar de reprocessar o que não mudou.
Em vez de carregar tabelas inteiras diariamente, a arquitetura deve usar padrões incrementais:
-
Watermark por data de alteração.
-
Particionamento de tabelas grandes.
-
Reprocessamento seletivo.
-
Separação entre carga histórica e carga diária.
-
Tratamento de deleções e atualizações tardias.
-
Orquestração por dependência e criticidade.
Uso correto de Lakehouses e Warehouses
Lakehouse e Warehouse não são escolhas estéticas. Eles atendem necessidades diferentes e podem coexistir.
Um lakehouse é especialmente útil para cenários de engenharia de dados, arquivos em formato aberto, Delta tables, processamento distribuído e integração com notebooks. Um warehouse tende a ser mais familiar para consultas SQL analíticas, modelos relacionais e consumo por times acostumados com data warehouses tradicionais.
A decisão deve considerar volume, perfil do time, latência necessária, padrões de consulta, governança e ferramentas de consumo.
Direct Lake para evitar cópias desnecessárias
O Direct Lake é um dos recursos mais estratégicos do Fabric porque permite que modelos semânticos leiam dados diretamente do OneLake em formato Delta, reduzindo a necessidade de importações tradicionais em determinados cenários.
Isso pode trazer ganhos importantes:
-
Menos duplicação de dados.
-
Menor janela de atualização.
-
Redução de etapas intermediárias.
-
Maior alinhamento entre camada de dados e camada semântica.
Mas Direct Lake não é mágico. Ele exige modelagem adequada, boas práticas no armazenamento Delta, controle de cardinalidade, desenho semântico e entendimento dos limites do recurso. Quando bem aplicado, pode ser um diferencial técnico e financeiro.
Mirroring e shortcuts como estratégia de modernização
Recursos como mirroring e shortcuts ajudam a aproximar dados do Fabric sem transformar cada integração em um projeto pesado de cópia.
Shortcuts podem conectar dados já existentes no OneLake ou em outros locais suportados, reduzindo movimentação desnecessária. Mirroring pode simplificar a replicação de fontes compatíveis para cenários analíticos.
A pergunta que deve orientar a arquitetura é: precisamos copiar este dado ou precisamos acessá-lo com governança e performance?
Modelagem semântica e DAX
Para muitos executivos, modelo semântico é invisível. Para o usuário final, ele é a diferença entre confiança e frustração.
Otimizações frequentes incluem:
-
Redução de colunas não utilizadas.
-
Separação clara entre fatos e dimensões.
-
Uso adequado de tipos de dados.
-
Remoção de cardinalidade desnecessária.
-
Criação de medidas DAX mais simples e reutilizáveis.
-
Revisão de relacionamentos.
-
Uso de agregações quando aplicável.
-
Incremental refresh para tabelas grandes.
-
Padronização de calendários e métricas corporativas.
Um DAX complexo pode ser brilhante em uma demonstração e péssimo em produção. Liderança técnica é saber quando a solução elegante é uma modelagem melhor, não uma medida maior.
Migração seletiva de Dataflows para Pipelines e Notebooks
Nem todo Dataflow precisa ser migrado. Mas quando Dataflows sustentam cargas críticas, volumosas ou difíceis de monitorar, vale avaliar uma migração para pipelines e notebooks.
Essa migração pode trazer:
-
Melhor controle de execução.
-
Parametrização.
-
Reuso de código.
-
Versionamento.
-
Observabilidade.
-
Separação de camadas.
-
Mais clareza entre ingestão, transformação e consumo.
A melhor abordagem é seletiva: priorizar os Dataflows mais caros, frágeis ou estratégicos.
Governança: a diferença entre projeto e plataforma
O fim do Trial também força uma conversa que muitas empresas adiam: Fabric não deve ser tratado apenas como ferramenta. Ele precisa ser operado como plataforma.
Isso exige governança em quatro dimensões.
1. Governança de ambientes
Workspaces precisam representar responsabilidades claras. Misturar desenvolvimento, homologação e produção no mesmo espaço aumenta risco, dificulta auditoria e atrapalha a sustentação.
Um padrão comum é separar:
-
Workspaces de desenvolvimento.
-
Workspaces de homologação.
-
Workspaces de produção.
-
Workspaces por domínio de negócio.
-
Workspaces compartilhados para componentes reutilizáveis.

2. Governança de segurança
A democratização de dados não significa liberar tudo para todos. É preciso definir:
-
Quem pode criar workspaces.
-
Quem pode publicar artefatos.
-
Quem pode compartilhar relatórios.
-
Quais dados exigem RLS, OLS ou mascaramento.
-
Como acessos são revisados.
-
Como dados sensíveis são classificados.
-
Quais grupos de segurança sustentam a operação.
3. Governança de desenvolvimento
Sem padrões de desenvolvimento, cada equipe cria sua própria versão da verdade. Isso afeta custo, performance e confiança.
Boas práticas incluem:
-
Convenção de nomes.
-
Padrão de camadas de dados.
-
Templates de pipelines.
-
Repositórios Git.
-
Revisão de código para notebooks e scripts.
-
Deployment pipelines.
-
Critérios mínimos para publicação em produção.
-
Documentação de linhagem e ownership.
4. Governança financeira
Capacidade sem FinOps vira surpresa. A organização precisa acompanhar consumo como acompanha qualquer outro recurso cloud.
Indicadores úteis:
-
Consumo por workspace.
-
Consumo por workload.
-
Picos por horário.
-
Tendência semanal e mensal.
-
Custo por domínio de negócio.
-
Itens sem dono.
-
Workloads ociosos.
-
Jobs com falha recorrente.
O objetivo não é criar burocracia. É permitir que a empresa cresça com controle.
CI/CD no Fabric: por que isso virou assunto executivo
CI/CD não é apenas uma pauta técnica. Em ambientes de dados, CI/CD reduz risco operacional.
Quando relatórios executivos, indicadores comerciais, métricas financeiras e pipelines críticos são alterados manualmente em produção, a empresa fica dependente de memória individual e procedimentos informais. Isso pode funcionar em times pequenos. Não sustenta escala.
Uma esteira madura deve contemplar:
-
Controle de versão.
-
Separação de ambientes.
-
Revisão antes da promoção.
-
Deploy automatizado sempre que possível.
-
Parametrização por ambiente.
-
Testes de dados e validações de refresh.
-
Plano de rollback.
-
Registro de alterações.
Para gestores de TI, isso reduz incidentes. Para gestores de contas e áreas de negócio, isso aumenta confiança nos números usados em reuniões, negociações e decisões comerciais.
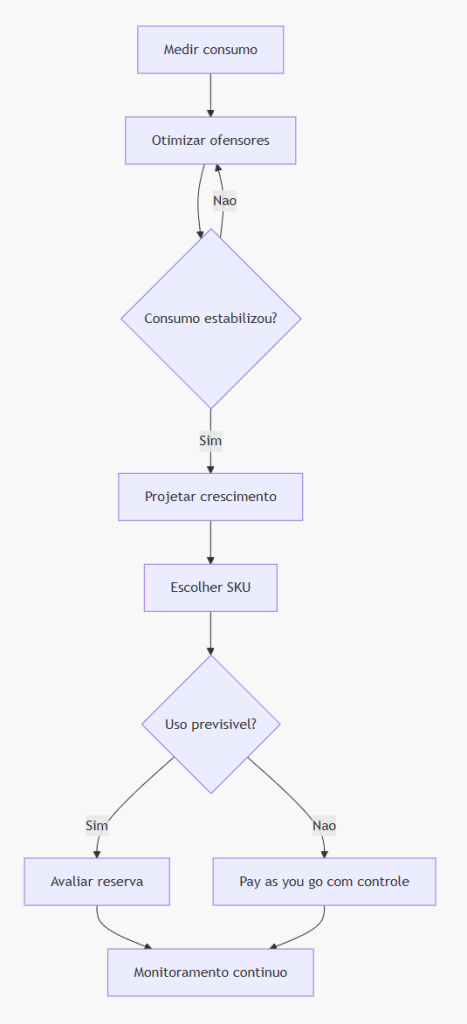
Como dimensionar a capacidade correta
Dimensionar capacidade é uma decisão técnica, financeira e operacional. O erro está em começar pelo SKU. O correto é começar pelo consumo.
Um processo recomendado:
-
Inventariar workspaces e artefatos.
-
Classificar criticidade dos workloads.
-
Medir consumo atual e estimado.
-
Identificar picos e concorrência entre cargas.
-
Otimizar os maiores ofensores.
-
Separar cargas por prioridade quando necessário.
-
Simular cenários de SKU.
-
Definir modelo de contratação: pay-as-you-go, reserva ou combinação.
-
Implantar monitoramento contínuo.
-
Revisar mensalmente consumo, performance e backlog de otimização.
Nem sempre a resposta será reduzir SKU. Às vezes a empresa precisa de uma capacidade maior, mas com clareza de motivo. A diferença é contratar por evidência, não por ansiedade.
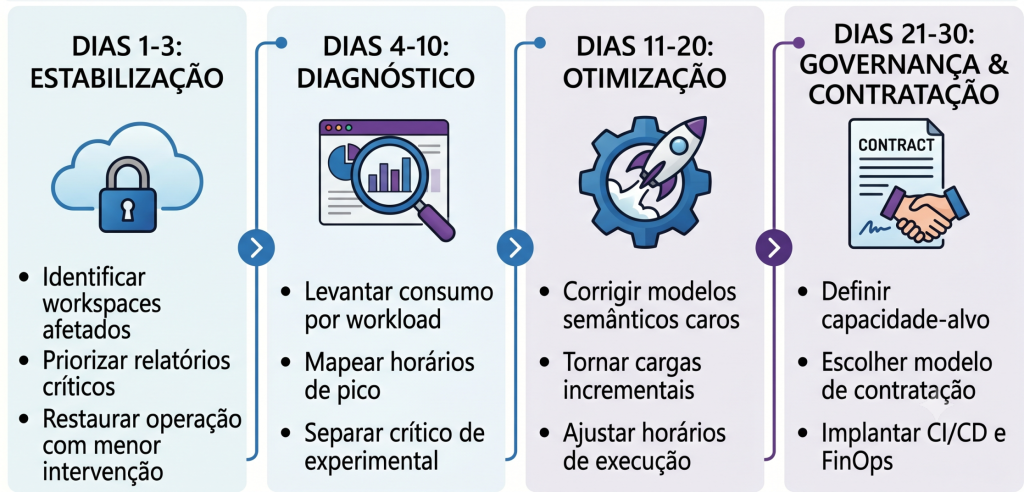
Roteiro prático para os próximos 30 dias
Para empresas impactadas pelo fim das renovações do Trial, um plano pragmático de 30 dias pode evitar decisões ruins.
Dias 1 a 3: estabilização
-
Identificar workspaces afetados.
-
Mapear relatórios, modelos e pipelines críticos.
-
Definir responsáveis por cada carga.
-
Restaurar operação prioritária com a menor intervenção possível.
-
Evitar contratações permanentes antes do diagnóstico.
Dias 4 a 10: diagnóstico
-
Levantar consumo por workload.
-
Identificar refreshes e jobs mais pesados.
-
Mapear horários de pico.
-
Separar cargas críticas de cargas experimentais.
-
Avaliar riscos de segurança e compartilhamento.
Dias 11 a 20: otimização
-
Corrigir modelos semânticos mais caros.
-
Revisar DAX crítico.
-
Transformar cargas full em incrementais.
-
Migrar Dataflows problemáticos quando fizer sentido.
-
Ajustar horários de execução.
-
Remover artefatos duplicados ou sem dono.
Dias 21 a 30: governança e contratação
-
Definir capacidade-alvo com base em evidências.
-
Decidir entre pay-as-you-go e reserva.
-
Separar ambientes.
-
Implantar políticas de desenvolvimento e segurança.
-
Criar rotina de monitoramento de capacidade.
-
Formalizar backlog de melhorias.
O alerta para os times técnicos
Se você atua no time técnico, este momento é uma oportunidade de elevar a conversa. O fim do Trial não é apenas um problema de licença. É uma chance de mostrar onde a plataforma precisa amadurecer.
Algumas perguntas que devem entrar no radar imediatamente:
-
Quais objetos em produção não têm dono claro?
-
Quais pipelines reprocessam histórico sem necessidade?
-
Quais modelos semânticos concentram lentidão ou falhas?
-
Quais relatórios são realmente críticos para o negócio?
-
Quais cargas poderiam usar Direct Lake?
-
Quais integrações poderiam se beneficiar de mirroring ou shortcuts?
-
Quais Dataflows deveriam virar pipelines ou notebooks?
-
Quais workspaces misturam experimento e produção?
-
Quais decisões dependem de processos manuais?
Responder essas perguntas com dados posiciona o time técnico como protagonista, não como área reativa.
O alerta para gestores de TI e gestores de contas
Para gestores, a principal mensagem é: não trate o fim do Trial como uma simples compra de capacidade. Trate como uma decisão de plataforma.
O Fabric pode acelerar a estratégia de dados da empresa, mas precisa ser conduzido com método. Sem isso, o custo cresce, a performance oscila e a confiança diminui. Com arquitetura e governança, a plataforma permite consolidar dados, reduzir silos, acelerar entregas e melhorar a tomada de decisão.
Gestores de contas e líderes próximos das áreas de negócio também devem acompanhar essa discussão. Dashboards comerciais, análises de carteira, margens, forecast, churn, pipeline de vendas e indicadores de atendimento dependem de uma cadeia técnica que precisa estar saudável. Quando a capacidade falha, o impacto chega na conversa com o cliente.
O papel da liderança é garantir que a empresa não compre apenas processamento. Ela deve comprar previsibilidade, continuidade e capacidade de evolução.
Conclusão: o fim do Trial pode ser o começo da maturidade
O encerramento das renovações do Trial do Microsoft Fabric pegou muitas empresas em um momento delicado. Ambientes que nasceram como prova de conceito viraram operação. Workloads criados em condição generosa agora precisam caber em orçamento real. E decisões que pareciam técnicas passaram a ter impacto direto na gestão.
Mas esse cenário também abre uma oportunidade importante. Ao analisar consumo, otimizar modelos, modernizar pipelines, aplicar Direct Lake quando fizer sentido, usar lakehouses e warehouses com critério, adotar mirroring e shortcuts de forma estratégica, migrar Dataflows problemáticos e implantar governança com CI/CD, a empresa deixa de reagir ao fim do Trial e passa a operar o Fabric como plataforma corporativa.
A Power Tuning possui know-how de ponta a ponta para apoiar empresas nesse processo: diagnóstico de ambiente, otimização de capacidade, arquitetura Fabric, modelagem semântica, performance Power BI, governança, segurança e CI/CD.
Se a sua empresa foi impactada pelo fim das renovações do Trial ou quer evitar uma contratação de capacidade sem clareza técnica, agende uma conversa com nosso time:
https://powertuning.com.br/reuniao-bi
Uma decisão bem tomada agora pode reduzir custo, evitar incidentes e transformar o Microsoft Fabric em uma base sólida para a estratégia de dados da empresa.
Artigo desenvolvido por Alison Pezzott (Head of BI & Analytics).
